Generate Livebooks with an LLM
So many loops…
Livebooks are a great way to explore code, run examples, and learn interactively. Funx is fully documented, so what would it take to turn its docs into Livebooks?
There are plugins that convert docs automatically, but I wanted slightly different results: cleaner imports and file organization that made sense inside the Livebook interface.
That left two options: fork a plugin and build a bespoke tool for Funx, or run the output and fix it by hand. Neither felt worth it. A plugin wouldn’t pay back the effort, and hand-editing breaks my first rule: never maintain docs in two places. And for the love of Pete, never do it by hand.
So I wondered. Could an LLM, stochastic by nature, act like a deterministic build tool? And could it do that without burning through a day’s worth of tokens?
The answer was: sort of.
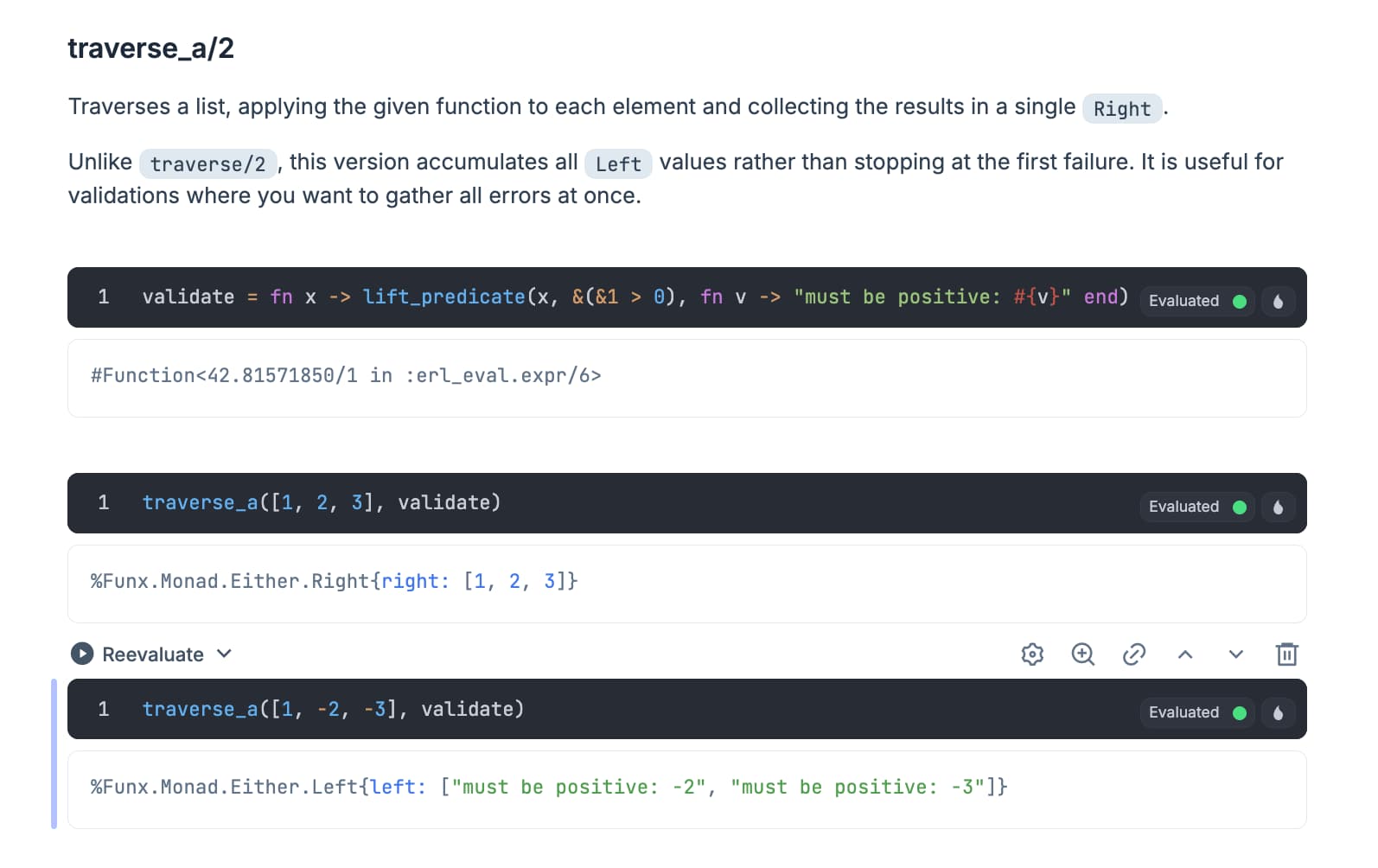
Livebooks
My favorite way to run a group of Livebooks is locally with Docker.
-
Clone funx:
git clone https://github.com/JKWA/funx.git cd funx -
Start Livebook using Docker Compose:
docker compose up -
Open your browser to http://localhost:8090
-
Login password:
funxlib_12char
You can also open them in your installed Livebook
Training the LLM
The LLM had to learn how to transcribe, verify, and refine its output through repeated passes. Each loop slightly improved the usage rules—because we weren’t just generating Livebooks, we were building the tool that would.
Start small: set a reasonable starting context
- Confirm it understands Livebook
- Show one
.exfile and verify it sees the docs - Set output target:
livebooks/and mirror thelib/tree - Generate one Livebook file
- Have it self-evaluate to see if it can tell when it makes mistakes
- Give feedback and correct mistakes together
- Have it create
usage-rules.mdand write its context - Review and clarify the usage rules
- Repeat with a new small file
Focus on transcription: transcription mistakes are worse than Livebook formatting mistakes
- Review the rules and focus on transcribing exactly, no rewrites
- Run on the generated file, have it self-evaluate
- Provide feedback, fix issues, rerun until consistent
- Have it update
usage-rules.md, then review - Work on a new, slightly larger file
- Repeat until it gets it right and can verify its work
Scale up: avoid burning tokens due to inefficiency
- Ask it to find the most efficient strategy for accomplishing its task
- Confirm and adjust
- Start with a few files, have it confirm its work
- Have it update
usage-rules.md - Repeat with larger batches
Crawl: evaluate periodically, not for every file
- Process all
.exfiles - At intervals, have it self-evaluate and correct
- Have it update
usage-rules.md - Repeat until the crawl is complete
Double-check: it’s an LLM, so it will miss something
- Look for patterns of mistakes
- Ask the LLM to recognize, fix, and confirm
- Have it find the most efficient strategy for finding and fixing mistakes
- Run across all files
- Repeat as needed until errors are reduced
Takeaway
The LLM never became deterministic. It was the usual story, helpful but not perfect. But by prioritizing transcription above all else, it was more likely to get that part right.
I wonder if an LLM can use git diff to reprocess when docs change?